A few months ago, I built a Retrieval Augmented Generation (RAG) application using Spring AI, Elasticsearch and Ollama. The application was focused on Indian recipe recommendations and used a manually wired retrieval pipeline with:
- Spring Batch ingestion
- Elasticsearch vector indexing
- BM25 keyword retrieval
- Dense vector similarity search
- Manual context building
- LLM prompt orchestration
That implementation worked well and eventually became this article: Build a Production-Grade RAG Application with Spring AI, Elasticsearch and Ollama
But as the pipeline evolved, the code started exposing a common problem most RAG systems eventually hit.
The orchestration layer slowly becomes the application. Every new concern - query rewriting, metadata filtering, citations, memory management, retrieval fusion, streaming - gets stitched manually around the LLM call.
The system still works, but the architecture stops feeling composable. So I rebuilt the same RAG system using Spring AI Advisors. And surprisingly, the pipeline became dramatically cleaner.
Instead of manually coordinating every RAG step, the entire flow became declarative and modular.
What Changed in the New Architecture?
The earlier implementation was retrieval-first.
The newer implementation is pipeline-first.
Instead of manually preparing context before every LLM invocation, I introduced a layered advisor flow:
- QueryRewriteAdvisor
- ContextAdvisor
- CitationAdvisor
Each advisor performs exactly one responsibility and enriches the request context before handing control to the next advisor.
The result is a much more maintainable RAG architecture where retrieval, transformation, memory and response enrichment become composable middleware.
The source code can be found at GitHub - Spring AI RAG Pipeline
High-Level Pipeline
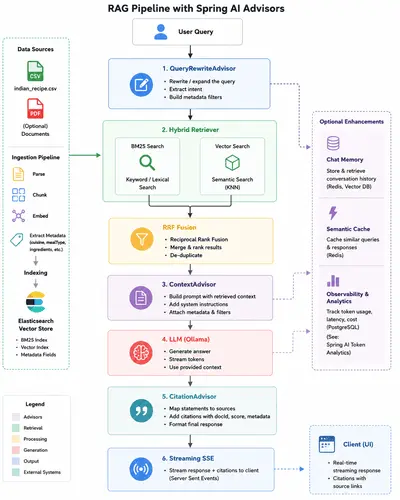
This architecture may look simple at first glance, but it solves several practical RAG problems elegantly:
- LLM-friendly query normalization
- Metadata-aware retrieval
- Hybrid semantic + lexical retrieval
- Composable advisor chaining
- Streaming token responses
- Structured citation generation
- Conversation memory support
Why Advisors Changed the Design
Spring AI Advisors behave similarly to interceptors or middleware pipelines. Each advisor can:
- Read the request
- Modify the request
- Inject context
- Observe responses
- Mutate the final output
This becomes extremely powerful in RAG systems because RAG itself is essentially a multi-stage orchestration problem.
Without advisors, your service layer starts accumulating responsibilities:
- Rewrite query
- Generate embeddings
- Retrieve documents
- Build prompt context
- Track citations
- Maintain memory
- Transform output
Eventually your "chat service" becomes a 700-line orchestration class. Advisors eliminate that problem entirely.
ChatClient Configuration
The entire advisor pipeline is wired directly into the ChatClient.
@Bean
public ChatClient chatClient(
ChatModel chatModel,
QueryRewriteAdvisor rewriteAdvisor,
MessageChatMemoryAdvisor memoryAdvisor,
ContextAdvisor contextAdvisor,
CitationAdvisor citationAdvisor) {
return ChatClient.builder(chatModel)
.defaultSystem(RECIPE_SYSTEM_PROMPT)
.defaultAdvisors(
rewriteAdvisor,
memoryAdvisor,
contextAdvisor,
citationAdvisor
)
.build();
}
This is one of the biggest architectural improvements compared to manual RAG orchestration. The pipeline becomes declarative.
Each advisor can focus entirely on a single concern while Spring AI coordinates execution ordering internally.
Query Rewriting Became Smarter
One of the biggest weaknesses in production RAG systems is raw user queries. Users rarely ask retrieval-friendly questions. For example:
"Suggest a spicy paneer curry under 30 mins with fewer ingredients"
This query contains:
- Semantic intent
- Cuisine preference
- Preparation constraints
- Ingredient constraints
Traditional vector search often misses these structured retrieval signals.
So instead of directly searching Elasticsearch, I first rewrite the query using a dedicated low-temperature LLM pipeline.
@Bean
public ChatClient rewriteClient(ChatModel chatModel) {
return ChatClient.builder(chatModel)
.defaultOptions(
OllamaChatOptions.builder()
.temperature(0.0)
)
.defaultSystem(QUERY_REWRITE_WITH_FILTER_SYSTEM_PROMPT)
.build();
}
The rewriting model converts natural language into structured retrieval metadata.
The system prompt explicitly instructs the model to generate normalized retrieval filters:
private static final String QUERY_REWRITE_WITH_FILTER_SYSTEM_PROMPT = """
You are a query rewriting engine for a recipe RAG system.
Extract structured retrieval filters from the user query.
Return ONLY raw JSON.
Rules:
- query = optimized semantic search query
- cuisine = cuisine type if present
- maxPrepTime = minutes if mentioned
- ingredients = ingredient list if mentioned
- maxIngredients = ingredient count limit if mentioned
Use null when unavailable.
""";
The advisor itself is intentionally minimal.
RecipeSearchRequest searchRequest = rewriteClient.prompt()
.user(query)
.call()
.entity(RecipeSearchRequest.class);
This is a subtle but important architectural improvement. The retrieval layer no longer depends directly on raw user language. Instead, retrieval receives normalized structured intent.
Context Propagation Through Advisors
The next important design improvement is context propagation. The rewritten query object gets attached directly into the advisor context.
ChatClientRequest updated =
chatClientRequest.mutate()
.context(Map.of(
"searchRequest", searchRequest
))
.build();
This avoids passing retrieval state manually across services. Every downstream advisor can access the same shared context. That becomes extremely useful later for:
- Retrieval
- Citation generation
- Observability
- Token analytics
- Memory management
Building a True Hybrid Retrieval Layer
One major limitation in many beginner RAG systems is over-reliance on vector search. Dense retrieval is powerful, but BM25 still matters. Especially in recipe search.
Ingredient names, cuisine labels and cooking terms often benefit heavily from lexical ranking. For example:
- "paneer butter masala"
- "chettinad chicken"
- "dal tadka"
Pure embedding similarity can sometimes over-generalize these domain-specific keywords. So the retriever executes both:
- BM25 retrieval
- Vector similarity retrieval
And both searches run concurrently.
CompletableFuture<List<RetrievalResult>> bm25Future =
CompletableFuture.supplyAsync(() -> {
try {
return bm25Search(request);
} catch (IOException e) {
throw new RuntimeException(e);
}
});
CompletableFuture<List<RetrievalResult>> vectorFuture =
CompletableFuture.supplyAsync(() -> {
try {
return vectorSearch(request);
} catch (IOException e) {
throw new RuntimeException(e);
}
});
This is an important production optimization. Retrieval latency compounds quickly in RAG systems.
If BM25 takes 120ms and vector search takes 180ms sequentially, you now have ~300ms retrieval overhead before the LLM even starts generation. Running them in parallel reduces retrieval latency significantly.
Metadata Filtering Inside Elasticsearch
One of the most useful upgrades in the new implementation is metadata-aware filtering. The rewritten query extracts structured filters which are directly injected into Elasticsearch queries.
if (request.getCuisine() != null) {
b.filter(f -> f.term(t -> t
.field("cuisine")
.value(request.getCuisine() + " Recipes")
));
}
Preparation time filtering is also applied at retrieval time:
if (request.getMaxPrepTime() != null) {
b.filter(f -> f.range(r -> r
.number(n -> n
.field("prepTime")
.lte(
request.getMaxPrepTime()
.doubleValue()
)
)
));
}
This dramatically improves retrieval precision. Without metadata filtering, the LLM receives context that may be semantically relevant but operationally useless. For example:
- User asks for recipes under 20 minutes
- Retriever sends 90-minute recipes
- LLM still tries answering
That creates hallucination pressure. Filtering earlier in the pipeline reduces that problem substantially.
Why I Added Reciprocal Rank Fusion (RRF)
Once you introduce hybrid retrieval, the next problem becomes ranking. BM25 and vector similarity produce completely different score distributions. You cannot reliably merge raw scores directly.
This is exactly where Reciprocal Rank Fusion becomes extremely effective. Instead of merging raw scores, RRF merges ranking positions. The idea is simple:
- If a document ranks well across multiple retrieval strategies, boost it heavily
- If a document ranks well in only one strategy, give it moderate weight
This usually produces significantly more stable retrieval quality compared to score normalization.
In practice, RRF improved retrieval consistency for recipe discovery queries substantially. Especially for mixed intent searches involving:
- Ingredients
- Cuisine
- Cooking style
- Preparation constraints
Taking Hybrid Search Further with Cross-Encoder Re-Ranking
Hybrid retrieval with BM25, vector search and RRF already produces strong retrieval quality. But in production-grade RAG systems, there is often one additional ranking layer added after retrieval: a cross-encoder re-ranker.
Instead of independently embedding the query and documents like traditional vector search, a cross-encoder evaluates both together and assigns a relevance score based on deeper semantic understanding.
For example for a given query quick spicy paneer recipe without onion, RRF may rank documents containing "panner" and "spicy" but may completely ignore "without onion" or "quick" but the cross encoder understands the interaction between entire query and entire chunk. So it properly prioritizes: no onion recipes and fast cooking recipes.
A common production pattern looks like this:
- Retrieve top candidates using BM25 + vector search
- Fuse results using RRF
- Send top N documents to a cross-encoder
- Re-rank documents based on semantic relevance
This additional ranking stage is usually more computationally expensive, which is why it is typically applied only on a small candidate set after retrieval. But when tuned correctly, it can significantly improve answer grounding and reduce irrelevant context reaching the LLM.
ContextAdvisor: The Actual RAG Injection Point
The ContextAdvisor is where retrieval results become actual LLM context.
List<RecipeVectorDocument> documents =
elasticRetriever.retrieve(searchRequest);
Once documents are retrieved, the advisor converts them into a structured prompt context.
String context = documents.stream()
.map(RecipeVectorDocument::getContent)
.collect(Collectors.joining(
"\n\n----------------------\n\n"
));
This gets injected into the request context:
return request.mutate()
.context(Map.of(
"searchRequest", searchRequest,
"documents", documents,
"ragContext", context
))
.build();
Notice something important here. The advisor does not directly modify the user prompt. Instead, it injects structured context variables. That keeps the retrieval layer decoupled from prompt engineering.
Clean Prompt Engineering Through Context Variables
The final system prompt remains surprisingly small.
private static final String RECIPE_SYSTEM_PROMPT = """
You are a helpful recipe assistant.
Use ONLY the provided context.
If answer is unavailable,
say you don't know in a funny way.
Context:
{ragContext}
Format recipe responses using markdown.
""";
This design is extremely maintainable. The prompt only focuses on:
- Behavior
- Formatting
- Grounding rules
Meanwhile, retrieval complexity stays completely outside the prompt layer. That separation becomes critical as RAG systems grow.
Streaming Responses End-to-End
One major UX improvement in the newer implementation is streaming. Instead of waiting for the entire response to complete, tokens stream progressively.
Flux<RagChunkResponse> contentStream = chatClient.prompt()
.user(chatRequest.getQuery())
.advisors(a -> a.param(
ChatMemory.CONVERSATION_ID,
chatRequest.getConversationId()
))
.stream()
.chatClientResponse()
This becomes particularly important with local LLMs. When running Ollama models locally, streaming dramatically improves perceived responsiveness. The user starts receiving tokens almost immediately instead of waiting for the full generation pipeline.
Improved Citation Handling
Citations are often treated as an afterthought in RAG tutorials. But in real applications, citations are critical. Especially when users need:
- Traceability
- Source confidence
- Verification
- Recipe attribution
The CitationAdvisor extracts citation metadata directly from retrieved documents.
return documents.stream()
.map(doc -> Citation.builder()
.title(doc.getRecipeName())
.sourceUrl(doc.getSourceUrl())
.score(doc.getScore())
.build())
.distinct()
.toList();
One particularly nice part of this implementation is that citations are appended as a final SSE event.
Flux<RagChunkResponse> citationStream =
Flux.defer(() -> {
List<Citation> citations =
citationsRef.get();
if (citations.isEmpty()) {
return Flux.empty();
}
return Flux.just(
RagChunkResponse.builder()
.type("CITATIONS")
.citations(citations)
.build()
);
});
This keeps streaming UX clean while still providing structured retrieval provenance.
Conversation Memory Support
Another major architectural improvement is memory integration. The pipeline now includes Spring AI chat memory directly as an advisor.
@Bean
public MessageChatMemoryAdvisor memoryAdvisor(ChatMemory chatMemory) {
return MessageChatMemoryAdvisor.builder(chatMemory)
.order(50)
.build();
}
And memory gets associated using conversation IDs.
.advisors(a -> a.param(
ChatMemory.CONVERSATION_ID,
chatRequest.getConversationId()
))
This is extremely useful for multi-turn recipe conversations. For example:
- "Suggest a spicy paneer curry"
- "Make it faster"
- "Now give me a healthier version"
Without memory, the retrieval layer loses conversational continuity. With advisors, memory becomes another composable pipeline concern.
Extending This Architecture Further
One of the biggest advantages of advisor-based RAG systems is extensibility. Adding new cross-cutting concerns becomes extremely straightforward.
For example, semantic caching can be added cleanly using Redis. I covered that architecture separately here: Build AI Chat App with Spring AI and Redis
That implementation demonstrates:
- Semantic caching
- Stateful chat memory
- Redis-backed conversation handling
- Reduced token consumption
Similarly, advisor pipelines become incredibly useful for observability.
I also implemented token usage analytics using Spring AI Advisors and PostgreSQL: Track Spring AI Token Usage Analytics
That article covers:
- Prompt token tracking
- Completion token tracking
- Latency metrics
- Cost analytics
- LLM observability
The important realization here is this:
Once your RAG architecture becomes advisor-driven, adding platform-level capabilities becomes dramatically easier.
Why This Architecture Feels Production Ready
The newer implementation feels fundamentally different from most tutorial-grade RAG applications. Not because it uses more AI features. But because responsibilities are isolated properly.
| Concern | Responsible Layer |
|---|---|
| Query normalization | QueryRewriteAdvisor |
| Memory management | MessageChatMemoryAdvisor |
| Hybrid retrieval | ElasticsearchHybridRetriever |
| Context injection | ContextAdvisor |
| Citation enrichment | CitationAdvisor |
| Streaming orchestration | SearchService |
That separation becomes increasingly valuable as the application evolves. For example, adding:
- Rerankers
- Guardrails
- Safety filters
- Semantic caching
- Analytics
- Prompt versioning
No longer requires rewriting the entire orchestration layer.
Lessons Learned While Building This
A few practical lessons became very clear during this refactor.
1. Pure Vector Search Is Rarely Enough
Hybrid retrieval consistently outperformed standalone embedding similarity. Especially for recipe and ingredient-heavy queries.
2. Query Rewriting Improves Retrieval More Than Prompt Engineering
Many developers over-invest in prompts while under-investing in retrieval quality. In practice, improving retrieval quality usually improves answer quality far more.
3. Streaming Matters More Than Raw Model Speed
Users tolerate slower generation much better when tokens stream progressively.
4. Advisor Pipelines Scale Architecturally
This was probably the biggest takeaway. Advisor-based composition keeps the system maintainable even as concerns grow.
Final Thoughts
The interesting part about modern RAG systems is that retrieval itself is no longer the hardest problem. Orchestration is. Once you move beyond demos, you quickly start dealing with:
- Retrieval quality
- Latency
- Memory
- Streaming
- Observability
- Citations
- Filtering
- Cost control
And that is exactly where Spring AI Advisors start shining. The framework stops feeling like a thin LLM wrapper and starts behaving like an actual AI orchestration platform.
The result is a RAG pipeline that is:
- Composable
- Maintainable
- Extensible
- Production-friendly
And honestly, after rebuilding the same application using advisors, I would find it difficult to go back to manual orchestration again.
Here is my recipe suggestion app suggesting me the best recipes.