
When I first stepped into AI and Machine Learning, I felt completely lost. Conversations sounded like: "kNN search", "embeddings", "fine-tuning", "overfitting", "vector similarity".
Coming from a Java backend background, I understood APIs, caching, and databases-but AI jargon felt like a different world.
But here's what changed everything:I stopped trying to learn AI theory and started mapping AI concepts to backend systems.
In this guide, I'll break down the most important AI terminologies in a way that made sense to me-and will help you confidently join AI discussions.
1. Core Concepts: The Foundation of Everything
- Model - A function that learns patterns (like a smart service class)
- Training - Feeding data so the model learns
- Inference - Using the model to predict (like calling an API)
- Dataset - Data used for training/testing
- Features - Inputs (like DTO fields)
- Labels - Expected output
Example: Fraud Detection System
Input: amount, location, time Output: fraud / not fraud
A model is simply: features -> function -> labels
2. Types of Machine Learning
- Supervised Learning - Data with labels (most backend use cases)
- Unsupervised Learning - Finding hidden patterns
- Reinforcement Learning - Learning via rewards
In real-world backend systems, you'll mostly deal with supervised + semantic AI.
3. Model Evaluation (How Good Is Your Model?)
- Accuracy
- Precision
- Recall
- F1 Score
Common Issues:
- Overfitting - Like hardcoding logic
- Underfitting - Too generic logic
Real-world insight: A model that performs well in testing may fail in production due to poor generalization.
4. Training Mechanics (What Happens Internally)
- Loss Function - Measures error
- Optimization - Reducing error
- Gradient Descent - How model learns
- Learning Rate - Speed of learning
Similar to tuning performance parameters in a backend system.
5. Neural Networks (Deep Learning Basics)
- Neuron
- Layer
- Weights & Bias
- Activation Function (ReLU, Sigmoid)
Think of it as a multi-layered processing pipeline transforming input to output.
6. NLP & Text Processing (Where Backend Meets AI)
This is where backend engineering and AI truly intersect-especially when dealing with text data.
- Tokenization - Breaking text into smaller units (tokens)
- Embedding - Converting tokens/text into vectors
- Vector - Numeric representation of text
- Semantic Search - Searching based on meaning, not keywords
What is Tokenization (and why it matters)?
Tokenization is the process of splitting text into smaller units called tokens. These tokens can be words, subwords, or even characters depending on the model.
Example:
Input: "Java developers love AI" Word Tokens: ["Java", "developers", "love", "AI"] Subword Tokens (used in LLMs): ["Java", "developer", "s", "love", "AI"]
Why this matters:
- LLMs don't read text-they process tokens
- Context window is measured in tokens, not words
- Token count directly impacts API cost (important in production)
- Better tokenization = better understanding of text
Real-world insight:
When building AI systems, you may hit limits like:
"Input too long (exceeds token limit)"
That's because the model processes tokens-not raw text.
Once tokenization happens, the next step is embedding generation, which powers semantic search.
Learn more: Elasticsearch Semantic Search Tutorial
7. Modern AI Terms (LLMs & Real Applications)
- LLM (Large Language Model)
- Prompt
- Context Window
- Fine-tuning
- RAG (Retrieval-Augmented Generation)
RAG = Search + AI = Most production AI systems today
8. Vector Search (The Real Engine Behind AI Search)
- Embedding Model
- Cosine Similarity
- kNN (k-Nearest Neighbors)
- HNSW
- Index
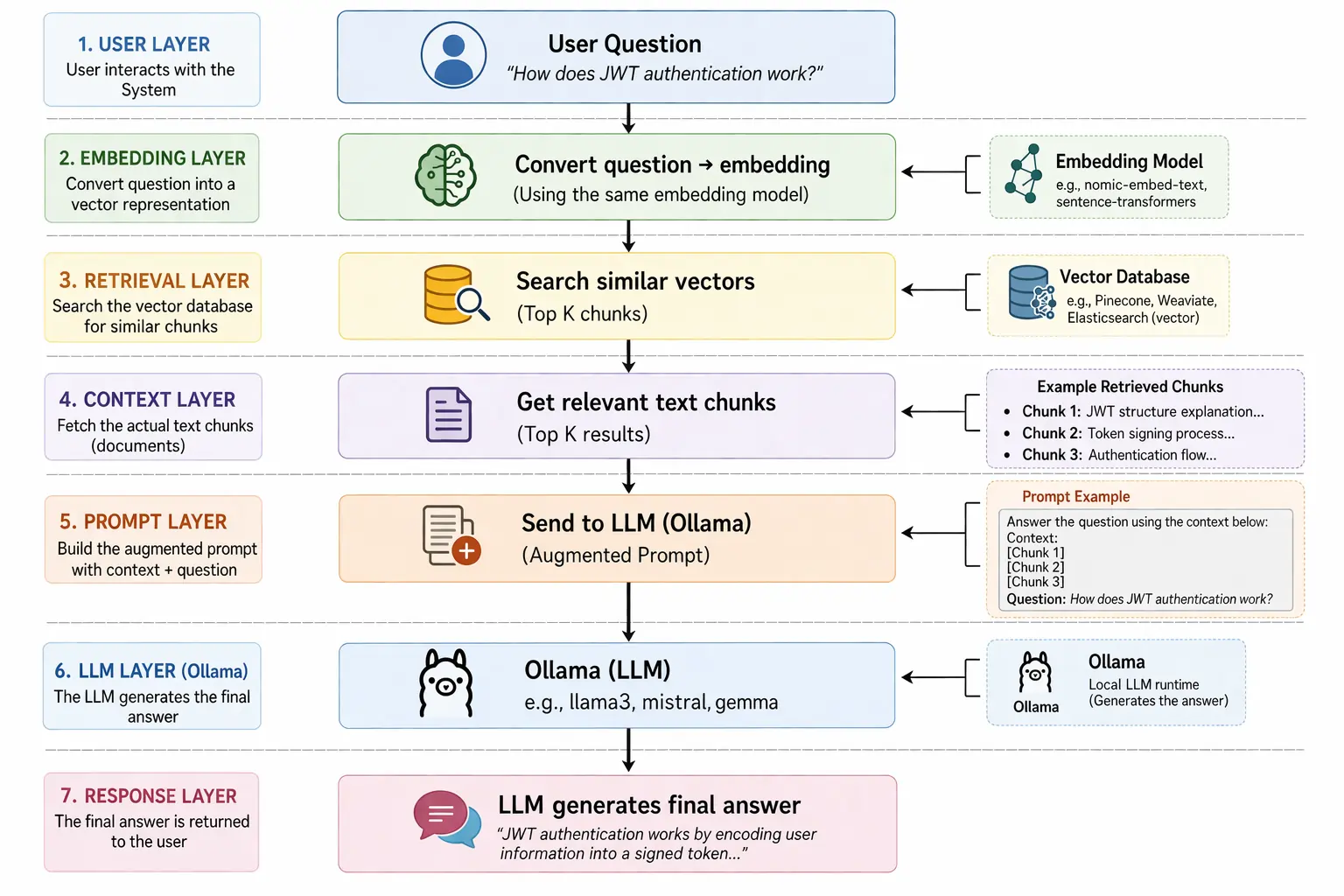
This is how systems understand similarity instead of exact matches.
Implementation: Spring Boot Elasticsearch Vector Search
Full AI search engine: AI Search Engine with Spring Boot & Elasticsearch
9. Semantic Caching (Performance Optimization with AI)
Traditional cache:
"What is AI?" != "Explain AI"
Semantic cache:
"What is AI?" ~ "Explain artificial intelligence"
- Query -> Embedding
- Search Redis
- Return similar cached result
Full guide: Semantic Caching with Redis and Spring Boot
10. Data Engineering Concepts (Critical but Ignored)
- Pipeline
- ETL (Extract, Transform, Load)
- Batch Processing
- Real-time Processing
AI systems fail more due to bad data pipelines than bad models.
11. Production & Scaling AI Systems
- Latency
- Throughput
- Scalability
- Model Drift
This is where Java developers dominate-AI still needs strong backend engineering.
The Mental Model That Changed Everything
User Query
|
Convert to Embedding
|
Vector Search (kNN)
|
Fetch Results / Cache
|
Return Response
Once you understand this flow, AI conversations become easy.
Final Thoughts
If you're a Java developer, you're already ahead:
- You understand systems
- You understand scalability
- You understand performance
AI is just an extension of these skills.
Start small:
- Build semantic search
- Add vector search
- Implement semantic caching
That's exactly how I learned-and it worked.
